(Deep Learning) 딥 러닝(Deep Learning) > Preview
딥 러닝(Deep Learning) 이란?
- 데이터에 존재하는 패턴을 복잡한 다계층 네트워크로 모델화하는 머신러닝의 일종
- Deep learning 은 문제를 모델화하는 방법으로, 컴퓨터 비전과 자연어 처리 같은 어려운 문제 또한 해결 가능 합니다.
- 트레이닝 할 모델의 Input 과 Output 사이에 숨겨진 계층(hidden layer)이 한 개 이상 존재 해야 하며. Deep learning 은 심층 신경망(Deep Neural Networks, DNN)을 사용하는 것을 의미합니다..
- 참고로 신경망 외에도, 다른 종류의 숨겨진 계층을 사용해 딥 러닝을 구현하는 알고리즘들이 소수 존재 합니다..
- 딥러닝 모델 트레이닝에는 아주 높은 컴퓨팅 성능이 필요 하며, 딥 러닝 모델 해석이 어려 것이 대표적인 단점 입니다.
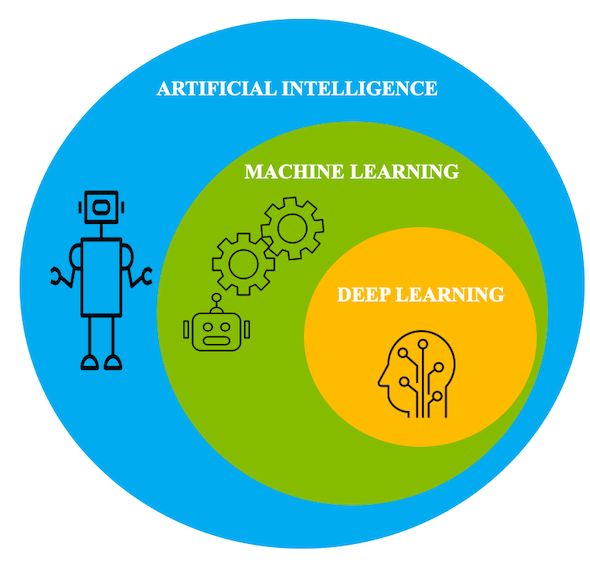
1. 딥 러닝 vs 머신러닝
- 딥 러닝은 머신러닝의 한 종류로 볼 수 있습니다.
2. 딥 러닝 애플리케이션 분야
- 자연어 처리 (Natural Language Processing, NLP)가 대표적인 예로
- 자동 요약(Automatic Summarization)
- 대용어 해소(Co-reference Resolution)
- 담화 분석(Discourse Analysis)
- 형태론적 구분(morphological segmentation)
- 개체명 인식(Named Entity Recognition, NER)
- 자연어 생성
- 자연어 이해
- POS(Part of Speech) 태깅
- 감성 분석(sentiment analysis)
- 스피치 인식(speech recognition)
- 등이 있다.
- 이미지 관련 문제의 경우
- 객체 탐지(Object detection)
- 객체 분할(Object segmentation)
- 이미지 스타일 전이(Image style transfer)
- 이미지 색상화(Image colorization)
- 이미지 재구성(Image reconstruction)
- 이미지 슈퍼레졸루션(Image super-resolution)
- 이미지 합성(Image synthesis) 등 이 있으며
- 이미지 분류는 비디오에서 개별 프레임을 추출해 비디오 관련 문제로 확대 적용 가능
- 비디오에서 탐지한 객체를 프레임 별로 추적할 수 있습니다.
- 각 프레임은 한장의 이미지 이기에..
3. 딥러닝 필수 개념
- 신경망
- ‘인공’ 신경망의 개념은 1940년대 처음 만들어졌으며
- 서로 연결된 한계 스위치(Threshold switches)를 통해 만든 인공 신경(뉴런) 네트워크를 학습시켜, 동물의 뇌와 신경계(망막 포함)처럼 패턴을 인식할 수 있게 만들 수 있다는 개념
- Backpropagation(역전파)
- 뉴런(신경 단위)
- 모델화한 뉴런은 어떨까? 각각 연결된 뉴런의 아웃풋(많은 경우 가중합과 함께)을 전이시키는 전파 함수(Propagation function)를 갖고 있습니다.
- 이 전파 함수의 아웃풋은 활성화 함수(Activation function)로 전달된다. 인풋이 한계 값을 초과할 때 작동을 시작하는 함수
- 활성화 함수(Activation function)
- 논리(Logistic), 시그모이드 함수(Sigmoid function), 쌍곡선 탄젠트(hyperbolic tangent), ReLu(Rectified Linear Unit)가 여기에 해당된다.
- 빠른 수렴(Convergence)에는 일반적으로 ReLU가 가장 좋다 그러나 학습 계수(Learning rate)를 너무 높게 설정하면 트레이닝 동안 뉴런이 '죽는’ 문제가 있으며
- 활성 함수 아웃풋을 아웃풋 함수로 전달할 수 있습니다.
- 신경망 토폴로지
- 피드포워드 망(Feed-forward network)에서 뉴런은 별개의 계층으로 구성된다. 1개의 인풋 계층, 몇 개의 숨겨진 처리 계층, 1개의 아웃풋 계층
- 각 계층의 아웃풋은 다음 계층으로만 전달
- 빠른 연결 형태를 가진 피드포워드 망의 경우, 일부 연결이 하나 이상의 중간 계층을 건너뛸 수도 있으며
- 순환 신경망(Recurrent Neural Network, RNN)의 경우, 뉴런은 직접, 또는 다음 계층을 통해 간접적으로 스스로에게 영향을 줄 수 있습니다.
- 트레이닝
- 신경망 학습의 지도 학습(Supervised learning)은 다른 머신러닝과 유사하게 이뤄진다. 네트워크에 트레이닝 데이터 그룹을 제시하고, 네트워크 아웃풋을 원하는 아웃풋과 비교하고, 오류 벡터를 생성하고, 오류 벡터를 토대로 네트워크에 수정을 적용합니다.
- 수정을 적용하기 앞서 함께 실행하는 트레이닝 데이터 배치를 에포크(Epoch)라고 부릅니다.
- 좀 더 세부적인 내용을 설명하자면, 오차역전파는 모델의 가중치 및 편향에 대해 오류(또는 대가) 함수의 기울기를 사용해 오류를 최소화시킬 수정의 방향을 찾으며,
- 최적화 알고리즘(optimization algorithm)과 학습 계수 변수(learning rate variable) 이 두 가지가 수정을 적용하는 것을 통제합니다.
- 통상 수렴이 보장되고, ReLU 뉴런이 죽는 문제를 방지하기 위해 가능한 작아야 합니다.
- Optimizer
- 신경망의 옵티마이저(Optimizers)는 일반적으로 경사 하강(Gradient descent) 알고리즘을 사용해 오차 역전파를 견인 합니다.
- 임의로 선택한 미니-배치(확률적 경사 하강)을 최적화하는 등 국소 최소한도 문제가 발생하는 것을 피하고, 경사에 탄성 수정치를 적용하는 데 도움을 주는 메카니즘을 사용하는 경우도 많습니다.
- 일부 최적화 알고리즘은 경사(기울기) 기록들인 AdaGrad, RMSProp, Adam을 조사해 모델 파라미터의 학습 계수를 조정 합니다.
- 다른 모든 머신러닝과 마찬가지로, 별개의 검증 데이터 세트를 대상으로 신경망의 예측치를 확인할 필요가 있다. 이렇게 하지 않으면, 일반화된 예측 도구가 될 학습 대신 인풋만 기억하는 신경망이 만들어질 위험이 있습니다.
4. 딥 러닝 알고리즘
- 대부분의 딥 러닝에 DNN (Deep Neural Network) 을 사용하며
- CNN(Convolutional Neural Networks)는 컴퓨터 영상에 많이 사용
- CNN은 통상 콘볼루션, 풀링, ReLu, 완전 연결, 손실(loss) 계층을 사용
- 풀링 계층은 일종의 비선형 다운 샘플링을 실시합니다.
- 완전 연결 계층의 경우, 뉴런은 앞선 계층의 모든 활성체와 연결 됩니다.
- 손실 계층의 경우, 예측한 레이블과 진짜 레이블 간 편향을 파악해 조정하는 네트워크 트레이닝에 대해 계산 합니다.
- 분류에는 소프트맥스(Softmax)나 크로스 엔트로피(Cross-entropy) 손실 함수,
- 회귀에는 유클리드(Euclidean) 손실 함수를 사용
- RNN(Recurrent Neural Networks) , LSTM(Long Short-Term Memory) 네트워크와 어텐션(Attention) 기반 신경망의 경우 자연어, 기타 시퀀스 프로세싱에 주 사용.
- feed forward 신경망은 input 에서 hidden layer, output 순으로 정보가 전달.
- 이는 네트워크가 한 번에 1개의 상태만 처리하도록 제약.
- RNN의 경우, 정보가 순환식으로 흐른다.
- 따라서 네트워크는 이전의 아웃풋을 기억하게 됩니다..
- 이를 통해 시퀀스와 시계열을 분석할 수 있습니다.
- RNN에는 2가지 일반적인 문제가 있다.
- 경사도를 중첩시켜 쉽게 고칠 수 있는 ‘경사도 폭발(Exploding gradients)’ 문제와 쉽게 고치기 힘든 ‘경사도 사라짐(Vanishing Gradients)’ 문제
- LSTM의 경우,
- 가중치를 수정하는 방법으로 이전 정보를 잊거나, 기억하도록 만들 수 있다.
- 이는 LSTM에 장단기 기억 능력을 제공하며, ‘경사도 사라짐’ 문제를 해결한다. LSTM은 과거 인풋의 수백 시퀀스를 처리할 수 있습니다.
- Attention 모델은 인풋 벡터에 가중치를 적용하는 일반화된 게이트
- 계층적인 뉴럴 어텐션 인코더는 여러 어텐션 모듈 계층을 사용, 수 많은 과거 인풋을 처리
- 랜덤 포레스트(Random Forests)
- 다양한 분류와 회귀 문제에 유용하지만 신경망이라 할 수 없습니다.
- DNN이 아닌, 또 다른 종류의 딥 러닝 알고리즘이 랜덤 포레스트
- 랜덤 포레스터는 수 많은 계층으로부터 구성
- 그러나 뉴런이 아닌 의사결정 트리로부터 구성.
- 또 아웃풋은
- 개별 트리의 통계적인 예측치 평균이다(분류의 경우 최빈값, 회귀의 경우 평균).
- 랜덤 포레스트는 임의성(무작위성, 확률성)을 갖습니다.
- 개별 트리에 부트스트랩 총계치를 사용하고(일명 bagging), 임의의 특징 하위 집합을 가져오기 때문 입니다.
5. 딥 러닝 프레임워크의 종류
- 딥 러닝 프로그램을 만들기 위해 딥 러닝 프레임워크를 사용하는 것이 훨씬 더 효율적
- GPU와 기타 액셀레이터(가속기)와 함께 사용할 수 있도록 최적화
- 주요 프레임워크는
- 파이썬(Python)이 기본인
- 구글이 만든 텐서플로우
- 텐서플로우에서 인기있는 고수준 API는 케라스(Keras) 이며
- 다른 백엔드 프레임워크와 함께 사용할 수도 있습니다.
- 페이스북 등의 파이토치(PyTorch)
- 동적 신경망을 지원한다는 특징
- 에포크마다 네트워크 특징을 변경할 수 있다는 의미
- 아마존 등의 MXNet
- 확장성이 더 뛰어나다고 주장
- MXNet에 반드시 필요한 고수준 API는 글루온(Gluon)
- IBM과 인텔 등의 체이너(Chaniner)가 파이토치에 일정 수준 ‘영감’을 줬다. 신경망을 실행(run)으로 정의하며, 동적 신경망을 지원하기 때문입니다.
- 자바(Java)와 스칼라(Scala)
- DL4J(Deeplearning4j)
- 스카이마인드(Skymind)에서 시작됐고 지금은 아파치 프로젝트가 된 DL4J는 아파치 스파크 및 하둡과 호환.
6. 딥 러닝 전이 학습
- 전이 학습(Transfer Learning)이란?
- 하나의 데이터 세트에 트레이닝 된 모델을 다른 데이터 세트에 맞춰 조정하는 프로세스 입니다.
- 전이 학습을 이용하는 것이 처음부터 모델을 트레이닝시키는 것보다 빠르다. 또 트레이닝에 필요한 데이터가 더 적습니다.
- 주로 Cloud 사업자가 제공하는 모델로는
- 구글 클라우드 AutoML(Cloud AutoML) : 영상, 번역, 자연어용 딥 러닝 전이 학습이 구현되어 있으며
- 애저 머신러닝 서비스(Azure Machine Learning Service) 또한 이와 유사한 딥 러닝 전이 학습 서비스를 맞춤형 비전, 맞춤형 스피치, 번역, 맞춤형 검색에 대해 제공하고 있습니다.
7. 딥 러닝 관련 책과 자료
- Neural Networks and Deep Learning, 저자: 마이클 넬슨
- A Brief Introduction to Neural Networks, 저자: 데이비드 크리셀
- Deep Learning, 저자: 여호수아 벤지오, 이언 굿펠로우, 애런 쿠르빌
- A Course in Machine Learning, 저자: 할 다움 3세
- TensorFlow Playground, 저자: 대니얼 스밀코프 및 샨 카터
- CS231n: Convolutional Neural Networks for Visual Recognition, 편찬: 스탠포드 대학
ref
Comments
Post a Comment