(Cloud) NCP > AI Service > OCR review
CLOVA OCR (optical character reader) Service review
문서를 인식하고, 사용자가 지정한 영역의 텍스트와 데이터를 정확하게 추출
CLOVA OCR (광학문자인식) 을 한번 사용해 본다면, NCP가 제공 중에 있는 AI Service 들 에 대하여 보다 쉬운 접근이 가능해질 거라 생각 하게 되어 review 를 해보고자 합니다.
[접근]
- Products & service : https://console.ncloud.com/dashboard
- OCR Service 경로 : Classic / CLOVA OCR / Domain

[이용 방식]
- 서비스 타입 General / Template / Document 선택에 따라 Text OCR / 템플릿 빌더 / Document 버튼이 노출되는 형식으로 서비스를 설정함
- Text OCR (텍스트만 추출) 과 Template 빌더 형태 (판독 영역 직접 지정을 통해 인식 값 추출 후 테스트 및 결과 전송이 가능) 는 서비스 타입에 따라 아래의 2가지 방식이 있으며
- 1. General OCR : 우리가 일반적으로 생각하는 png, jpg이미지 혹은 pdf 에 존재하는 text 들을 모두 읽어 오고자 하는 방식
- 2. Template OCR : 운전 면허증, 신용 카드, 주민 등록 등본 이미지 등 이미지내 정해진 특정 영역을 기준으로 text 들을 읽어 오는 방식
- Document 방식은
- 머신러닝 기반으로 문서의 의미적 구조를 이해하는 특화 모델 엔진을 탑재하여 입력 정보(key-value)를 자동 추출하는 방식
- 인식 모델로는 미리 정해진 사업자 등록증, 신용카드,영수증, 신분증, 명함이 제공 되며 이를 선택할 수 있게 되어 있습니다.
- 머신러닝 기반으로 문서의 의미적 구조를 이해하는 특화 모델 엔진을 탑재하여 입력 정보(key-value)를 자동 추출하는 방식
- 인식 모델로는 미리 정해진 사업자 등록증, 신용카드,영수증, 신분증, 명함이 제공 되며 이를 선택할 수 있게 되어 있습니다.
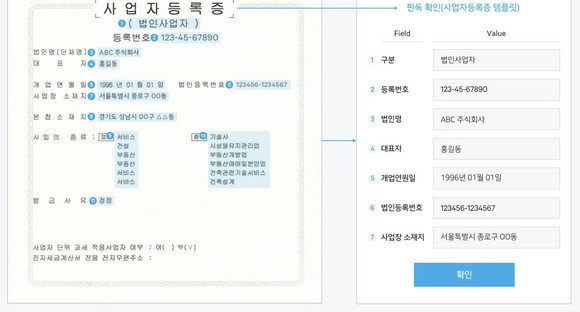
[이러한 Type 별 서비스를 이용하는 방법 또한 2가지로 구분 될 수 있습니다.]
- 1. NCP OCR 사이트에 접속해서 제공되는 UI 화면으로 접근 하는 방식으로 원하는 이미지 파일을 drag and drop으로 등록하고 텍스트를 인식 하는 방식과
- 2. 개발자들의 접근 방식인 외부의 App 또는 시스템에서 API 형태로 호출 하는 방식이 있습니다.
- API 형태로 호출 하는 방식의 경우 API Gateway 서비스를 필수적으로 생성 해야 하며
- 원하는 API (여기서는 OCR) 에 접근 할 수 있는 URL 을 만들어 이를 이용해야 합니다.
지금 까지 소개된 domain 과 API Gateway 가 준비 되었다면
외부에서 API Gateway 가 제공하는 URL 정보를 통해 생성된 domain 에 접근하여 OCR 서비스를 이용할 수 있습니다.
NCP 는 예제 코드 또한 친절하게 제공해 줍니다.
[CLOVA OCR Custom API]
import requests
import uuid
import time
import json
api_url = 'YOUR_API_URL' #OCR API URL 정보
secret_key = 'YOUR_SECRET_KEY' #가입후 생성한 Secret key
image_file = 'YOUR_IMAGE_FILE' #이미지 경로 지정
request_json = {
'images': [
{
'format': 'jpg',
'name': 'demo'
}
],
'requestId': str(uuid.uuid4()),
'version': 'V2',
'timestamp': int(round(time.time() * 1000))
}
payload = {'message': json.dumps(request_json).encode('UTF-8')}
files = [
('file', open(image_file,'rb'))
]
headers = {
'X-OCR-SECRET': secret_key
}
response = requests.request("POST", api_url, headers=headers, data = payload, files = files)
print(response.text.encode('utf8'))[CLOVA Document API]
import requests
import uuid
import time
import base64
import json
api_url = 'YOUR_API_URL'
secret_key = 'YOUR_SECRET_KEY'
image_file = 'YOUR_IMAGE_FILE'
with open(image_file,'rb') as f:
file_data = f.read()
request_json = {
'images': [
{
'format': 'jpg',
'name': 'demo',
'data': base64.b64encode(file_data).decode()
}
],
'requestId': str(uuid.uuid4()),
'version': 'V2',
'timestamp': int(round(time.time() * 1000))
}
payload = json.dumps(request_json).encode('UTF-8')
headers = {
'X-OCR-SECRET': secret_key,
'Content-Type': 'application/json'
}
response = requests.request("POST", api_url, headers=headers, data = payload)
print(response.text)Reference :
- ClOVA OCR 사용 가이드 : https://guide.ncloud-docs.com/docs/ocr-ocr-1-1
- CLOVA OCR Custom API : https://api.ncloud-docs.com/docs/ai-application-service-ocr-ocr
Comments
Post a Comment