(Cloud) AWS > AWS 기반 데이터 분석 환경 - "Amazon Redshift" review
Amazon Redshift
AWS 의 가장 빠르고 가장 널리 사용되는 "클라우드 데이터 웨어하우스에서 모든 데이터 분석" 을 주제로, 잠시 시간이 되어 AWS 기반 데이터 분석에 대한 강의를 들을 기회가 있었습니다.
AWS 는 자신들의 여러 비지니스 모델 중 하나로, 각 기업의 온프레미스 데이터 웨어하우스를 Amazon Redshift 로 마이그레이션 하는 것을 목표로 하는 것으로 보입니다.
문득, 개인 적으로 드는 생각은 어느 정도의 범위 또는 수준 까지 가능 할지 가 궁금해집니다.
각 기업들이 보유한 데이터 중 데이터 분석 효과가 크고 중요한 즉 보안 유지가 필요한 데이터를 "Cloud 데이터 웨어하우스" 로 구축 하고 일상화 하는데 얼마 만큼의 시간이 걸릴게 될지.. (아마도 의사 결정을 누군가는 내려야겠지만.. 누가? risk 를 감내할 만큼 효과가 있을 까요? 쉽지 않은 결정이라 생각 합니다.)
이러한 의구심을 뒤로 하고, 혹시 모를 미래를 준비하기 위해 강의 내용을 정리 해 보고자 합니다.
- 목 표 : AWS 기반 데이터 분석
- 목 차
- 분석 Trend
- 예시
- 어려움
- 완전 관리 형
- 서버 리스 형
- 분석 용 데이터 저장
- 초기 분석 아키텍처
- 내 용 (주요 사항)
- 분석 Trend
- 증가하는 데이터 량
- 복잡해진 데이터 요구 사항
- 발전하는 데이터 분석 기술의 발전
- Hadoop, Elasticsearch, Presto, Spark
- 최근에는 ML 관련 플랫폼도 많이 이용되는 추세
- 데이터 분석 예시
- insight 도출 , business 의사 결정 : 신규 사업 분석, 보안 분석 등
- 어려움
- 제약 사항 : 인원, 시간, 비용, 배움의 어려움
- 학습,설치, Poc, 운영 모두가 비용
- 적절한 서비스 선택과 아키텍처
- 데이터를 하나로 모으는 게 어려움
- 제약 사항을 극복하기 위해: 비용 효율, 더 빠르게, 핵심 비지니스에 접근, 낮은 위험에서 더 자주 실험
- 완전 관리 형 서비스 (AWS Managed Service)
- 설치 구축 운영 성능 튜닝은 기본으로 제공
- 직접 서버에 설치해서 운영하지 않아도 되는 완전 관리 형 분석 서비스 들
- Amazon EMR : AWS 에서 Spark ,Hadoop, Hive, Presto, HBase 및 기타 빅 데이터 앱을 쉽게 실행
- Amazon Redshift : 최초이자 가장 인기 있는 클라우드 데이터 웨어 하우스
- 데이터 레이트 & AWS 통합
- 무제하나 동시 액세스를 충족하기 위해 온-디맨드 무제한 컴퓨팅 용량 초과
- Apache Kafka :안전한 완전 관리 형 고가용성 서비스
- 실시간 스트리밍 처리
- 운영 분석
- 안전한 완전 관리 형 고가용성 Elasticsearch 서비스
- 서버 리스 형
- 관리 자동화를 넘어 SQL 이나 분석 스크립트만 돌림
- 빠르게 가성비 최고의 분석 솔루션 구축 가능, 작게 시작
- 인프라 구축 및 운영이 필요 없음
- 기본 구성
- Glue
- 다양한 방식으로 동일 데이터 분석
- 크롤러를 사용하여 데이터 스키마를 분석
- 식별자를 통하여 테이블 정의를 glue 데이터 카탈로그에 작성
- 실제 데이터 저장소에 연결
- 스키마 추론
- 로딩 작업 생성
- 작업을 실행 변환/전송 처리
- 모니터링
- S3 : 확장 가능한 저장소
- Kinesis : 실시간 데이터 및 비디오 스크림을 쉽게 수집,
- Anthena : 서버 운영 없이 데이터 카탈로그 기반으로 기본 SQL과 같은 경험
- DDL을 사용한 Create External Table
- Amazon QuickSight
- 분석 용 데이터 저장
- 쉽게 저장되고 안전하며 통합 되어 관리 되기 위해 S3에 모을 필요가 있다.
- 무한 확장 가능, 오브젝트 기반 소트로지, 전송중/암호화 지원
- 예로, 각각의 매출, 장바구니 사용자 별로 데이터를 모아 분석하는 방식에서 한 곳으로 모아 놓은 후 분석
- 일반적인 데이터 레이크 아키텍처
- 확장 가능한 데이터 레이ㅣ크
- 목적에 맞게 구축 된 데이터 서비스
- 원활한 데이터 이동
- 통합 거버넌스
- 성능과 비용 효율성
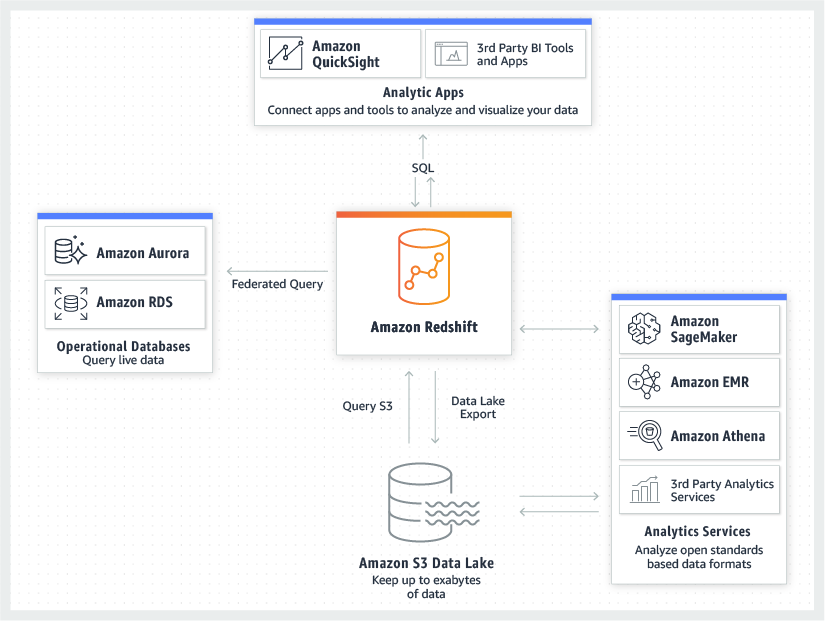
- 초기 분석 아키텍처
- AUQA - Advanced Query Accelerator
- S3 기반의 새로운 분산형 하드웨어 가속 처리 Layer , 여러 노드에서 병렬로 데이터 처리 가능
- Redshift Data Sharing
- 실시간으로 일관된 데이터를 공유하는 간단하고 직접적인 방법
- 개별 클러스터 구성을 설정 하여 성능, 비용을 최적화
- Redshift Machine Learning (ML)
- EMR on Amazon EKS
- EKS 에서 Apache spark job 실행
ref :
- Amazon Redshift : https://aws.amazon.com/ko/redshift/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc
Comments
Post a Comment